Datafusie is het combineren van verschillende gegevensbronnen tot gewenste informatie. Wanneer deze gegevens slim gecombineerd worden, bij voorkeur met een verkeersmodel, dan kan er veel meer informatie uit gehaald worden dan tot nu toe gebruikelijk is. Voor deze combinatie is het belangrijk om de relatie tussen de gemeten grootheden enerzijds en de gewenste informatie anderzijds, goed vast te leggen. Vervolgens kan door middel van een Kalman filter of een Bayesiaans netwerk de combinatie tussen metingen en model worden gemaakt. Hierdoor wordt alle beschikbare kennis gebruikt om tot goede informatie te komen. Deze meest verregaande vorm van datafusie is nog nergens geimplementeerd maar een case-study geeft aan dat het zeker mogelijk en zinvol is.
Inleiding[]
De uitdaging van monitoring is om verschillende meetgegevens om te zetten in zinvolle informatie. Bij verschillende complexe toepassingen (denk aan processen zoals het lanceren van een Space Shuttle en het bedienen van kerncentrales) wordt hiervoor gebruik gemaakt van datafusie. Datafusie is het slim combineren van verschillende gegevensbronnen, waardoor betere informatie kan worden geleverd dan op basis van de afzonderlijke bronnen alleen. Het gaat om het schatten van een toestand die niet direct kan worden gemeten en dus uit andere gegegevens moet worden berekend. In het verkeer kan worden gedacht aan dichtheden en reistijden in de nabije toekomst; deze kunnen worden berekend uit lusgegevens of reistijdmetingen. Worden deze twee meetmethoden door middel van datafusie aan elkaar gekoppeld, dan kunnen de gezochte grootheden beter worden voorspeld.
Waarom datafusie?[]
Er zijn verschillende argumenten om datafusietechnieken toe te passen. Volgens beschikbare literatuur leidt datafusie tot:
- betrouwbaardere informatie: meerdere sensoren kunnen immers een bepaalde toestand bevestigen;
- verhoogde nauwkeurigheid: inconsistente informatie door meetfouten kan worden omgezet in consistente informatie en kleinere fouten;
- verminderde ambiguïteit (dubbelzinnigheid): gegevens uit meerdere sensoren verminderen het aantal plausibele hypotheses;
- een robuuster monitoringsysteem: het falen van een sensor leidt niet tot het falen van het gehele systeem;
- een grotere ruimtelijke en temporele dekkingsgraad: het ene type sensor is wellicht beter dan het andere bij toepassing op een bepaalde plaats en tijd en onder bepaalde omstandigheden;
- verhoogde kostenefficiëntie: een combinatie van verschillende sensoren van gemiddelde kwaliteit (nauwkeurigheid, betrouwbaarheid) kunnen dezelfde performance halen als een set identieke en kwalitatief betere (maar duurdere) sensoren; ook zijn door slim te combineren in totaal wellicht minder sensoren nodig.
Aangezien verkeerssystemen zich dynamisch en non-lineair gedragen en omdat er door steeds meer verschillende systemen kan worden gemeten, lijkt datafusie een zeer veelbelovende mogelijkheid om met minder sensoren meer te meten. Een casus waarin dit wordt onderstreept is te vinden in 'Datafusie', NM magazine 2006-3, p22; hier blijkt dat gegevens uit inductielussen en Floating Car Data met datafusie goed kunnen worden gecombineerd. Met als resultaat: betere informatie dan van de afzonderlijke systemen.
De moeilijkheid van Datafusie[]
Datafusie is echter niet makkelijk te implementeren, het combineren van verschillende gegevenstypen is geen rechttoe rechtaan proces. Verschillende bronnen hebben een totaal andere betekenis over de ruimte en tijd. als voorbeeld nemen we het koppellen van gegevens uit een inductielus (bijv. lokaal 1 minuut gemiddelde snelheid) aan een reistijd over een langer traject. Ten eerste hebben deze grootheden een andere ruimtelijke betekenis (wegdoorsnede versus een traject) maar ze verschillen ook in betekenis over de tijd. De lokale meting stelt bijvoorbeeld een 1-minuutgemiddelde snelheid voor, een gemiddelde reistijd (die gelijk is aan lengte traject / de gemiddelde trajectsnelheid) geeft informatie over een tijdsperiode zo lang als de reistijd. De verschillen tussen deze gegevens wordt inzichtelijk gemaakt bij de uitleg over het verschil tussen puntsnelheid en trajectsnelheid
Onderdelen datafusie[]
Door gebruik te maken van a-priori kennis kunnen meetgegevens uit verschillende bronnen worden samengevoegd tot betrouwbare en robuuste informatie. In deze paragraaf wordt aangegeven hoe deze combinatie vorm kan krijgen bij het monitoren van verkeer. Hierbij wordt uitgegaan van drie onderdelen: de meetgegevens, de a-priori kennis en het algoritme om die twee zaken te combineren.
Meetgegevens[]
Data kan in verschillende formats en via verschillende communicatiekanalen worden aangeleverd. Voor het verwerken van multi-sensordata bestaan drie verschillende standaardmethoden: 1) direct fuseren van data; 2) data converteren naar systeemeigenschappen, die vervolgens centraal worden behandeld; 3) het individueel verwerken van elke sensor en pas op hoog niveau beslissen over de meting.
De eerste configuratie fuseert de data direct op het niveau van de sensor. Dit wordt gebruikt bij sensoren die basale fusie processen kunnen uitvoeren, zoals data alignement, object associatie en dergelijke. Als een set sensoren dezelfde fysische grootheid meet, dan kan de data direct worden gecombineerd. Dit kan bijvoorbeeld bij een serie inductielussen op een wegsegment. Technieken voor ruwe datafusie gebruiken normaliter klassieke schattingsmethoden, zoals kleinste kwadraten en de zogenoemde Kalman-filtering. Als de meetgegevens niet gelijksoortig of incompleet zijn, moet de data gefuseerd worden op basis van systeemeigenschappen of op beslisniveau.
De tweede configuratie gebruikt fusie op het niveau van systeemeigenschappen. Systeemeigenschappen worden afgeleid uit representatieve onderdelen van de meetgegevens, bijvoorbeeld regressieconstantes of zogenoemde Fourier transformatiecoëfficienten. Systeemeigenschappen worden uit de diverse meetgegevens geselecteerd en gecombineerd. Dit gebeurt in een vector van representatieve eigenschappen, waar vervolgens met behulp van bijvoorbeeld patroonherkenning informatie uit wordt gehaald. Een voorbeeld van deze aanpak is het gebruik van camera's en geluidssensoren om voertuigstromen te identificeren en te schatten op kritieke snelwegsegmenten.
De derde mogelijk configuratie combineert meetgegevens nadat elke sensor een eerste bepaling heeft gedaan van identificatie en locatie van een object. Technieken om op beslissingsniveau data te fuseren zijn bijvoorbeeld stemtechnieken en parameterdeductie. Geavanceerde camera's, in het bijzonder kleurencamera's, kunnen op deze wijze informatie en locatie van een object leveren.
Er is geen eenduidige voorkeur voor een van de drie genoemde methoden. De meeste datafusiesystemen zijn zelfs een hybride tussenvorm. Bij datafusiesystemen zoals die nu voor het leveren van verkeersinformatie worden ontwikkeld, gebruikt men voornamelijk de tweede configuratie. Zo kunnen bijvoorbeeld systeemeigenschappen als snelheid en intensiteit uit inductielussen centraal worden verzameld en gecombineerd met reistijden uit Floating Car Data.
A-priori kennis[]
Bij datafusie wordt behalve van meetgegevens ook gebruik gemaakt van a-priori kennis, in de vorm van een of ander model. Zo kan de wet van behoud van voertuigen worden gebruikt. Dit wil zeggen: het is zeker dat voertuigen niet zomaar verdwijnen of verschijnen, dus als de metingen dat aangeven moeten ze worden gecorrigeerd. Uiteraard is dit niet direct meetbaar. Maar wanneer op een bepaald wegvak structureel meer voertuigen binnenrijden dan eruit gaan, kan op basis van deze a-priori kennis worden gesteld dat de metingen gecorrigeerd moeten worden. Hiermee wordt echter slechts een zeer beperkt deel van onze kennis van verkeersgedrag gebruikt. Daarom ligt het meer voor de hand om bijvoorbeeld de fundamentele relatie te gebruiken. In theorie is het zelfs mogelijk om complexe online verkeersmodellen te gebruiken. Vraag is wel in hoeverre hiermee hogere betrouwbaarheid in het eindresultaat wordt bereikt. Over het algemeen blijken simpele modellen bij deze methode net zo goed te functioneren als complexe modellen.
Een andere bron van a-priori kennis is de database van reeds gemeten gegevens. Dit betekent dat het model wordt gevormd door de historische data. Een inconsistentie in de metingen wordt dan gezien als een afwijking, die wordt gladgestreken door uit te gaan van de historische data.
Fusie algoritme[]
De kracht van datafusie ligt in de combinatie van meetgegevens en a-priori kennis. Deze combinatie wordt gemaakt door een datafusie-algoritme. Hier worden enkele voorbeelden besproken, maar eerst volgt een uitleg van de eigenschappen waar het algoritme aan moet voldoen.
Zowel op basis van de meetgegevens als op basis van het model is de waarde voor de te bepalen grootheid berekend. Over het algemeen zijn dit twee verschillende waarden en ligt de "waarheid" in het midden. De taak van het fusie algoritme is om dit midden zo goed mogelijk te kiezen. Hierbij maakt een goed algoritme gebruik van een betrouwbaarheidsschatting van beide waardes; de meest betrouwbare waarde krijgt de zwaarste weging in een gewogen gemiddelde.
Kalman Filter[]
Deze paragraaf komt uit: 'Datafusie', NM magazine 2006-3, p22

Eenvoudig gezegd combineert een Kalman-filter metingen uit verschillende databronnen met de kennis van de systeemdynamica, weergegeven in een verkeersmodel. De figuur hiernaast geeft aan op welke manier dit gebeurt.
Toelichting: Stel dat er op tijdstip tk een schatting is van de toestand van het systeem dat wordt beschouwd. Dit kan bijvoorbeeld de intensiteit en snelheid zijn van het verkeer op de takken van een netwerk. Maar het kunnen ook de parameters zijn die het verkeersgedrag beschrijven, bijvoorbeeld het aandeel verkeer dat de afrit kiest. Met behulp van een verkeersmodel wordt op grond van deze geschatte toestand op tijdstip tk de toestand op tijdstip tk+1 voorspeld.
Omdat een verkeersmodel geen honderd procent nauwkeurige voorspelling kan geven, mag gevoeglijk worden aangenomen dat er sprake is van een zekere modelfout of -ruis. Door slim gebruik te maken van de beschikbare metingen, kan deze fout echter aanzienlijk worden verkleind. Het Kalman-filter doet dit in de zogenaamde correctiestap, op grond van het verschil tussen de echte metingen en de voorspelde metingen: gecorrigeerde_toestand(tk+1) = voorspelde_toestand(tk+1) + K (voorspelde_meting(tk+1) - meting(tk+1)) Deze voorspelde meting wordt berekend aan de hand van de voorspelde toestand, door het toepassen van de zogenoemde meetvergelijking: voorspelde_meting(tk+1) = h(voorspelde_toestand(tk)).
In de meetvergelijking staan de verschillende databronnen. Bij toepassingen in het verkeer kunnen dit door lussen gemeten intensiteiten en snelheden zijn, dichtheidsmetingen uit video, floating car data, reistijden uit kentekencamera’s, enzovoorts. Het opstellen van een goede meetvergelijking is echter lang niet altijd eenvoudig. De matrix K (ook wel de ‘Kalman gain’ genoemd) wordt grofweg bepaald op grond van de verhouding tussen de modelfout en de meetfout: is de meetfout relatief klein, dan zal de daadwerkelijke meting een groot gewicht krijgen. Dit betekent een grote correctie van de voorspelling. Is de meetfout relatief groot, dan zal juist een kleine correctie van de voorspelling plaatsvinden.
Een aardig bijproduct van een Kalman-filter is de zogenaamde covariantiematrix. Deze geeft weer hoe betrouwbaar de geschatte grootheden zijn. De matrix maakt het derhalve mogelijk te beoordelen of de schattingen van voldoende kwaliteit zijn, of dat er wellicht moet worden geïnvesteerd in het uitbreiden of verbeteren van de beschikbare verkeersmonitoringsystemen.
Indien verschillende soorten data (met verschillende meetfouten) worden gebruikt, dan beschrijft de Kalman gain bovendien op welke wijze de verschillende databronnen worden gecombineerd. Dit gebeurt op grond van de dynamische en ruimtelijke kenmerken van de meting en de meetfout. Zo heeft een lusmeting een relatief kleine fout, maar wordt alleen de toestand ter hoogte van de meetlus direct aangepast op grond van de beschikbare metingen. Floating car data bestrijkt juist een groter deel van het netwerk. Het heeft ook een veel grotere meetfout, omdat het hier om een meting van één enkel individu gaat. Dit betekent dat de gegevens leiden tot een correctie op een groter deel van het netwerk, maar dat deze correctie minder sterk is.
Zoals uit de case blijkt, zit de kracht juist in het combineren van dergelijke databronnen met verschillende kenmerken ten aanzien van de kwaliteit en de ruimtelijke beschikbaarheid.
Voor meer algemene informatie zie de Nederlandse of de Engelse wikipedia.
Bayesiaanse netwerken[]
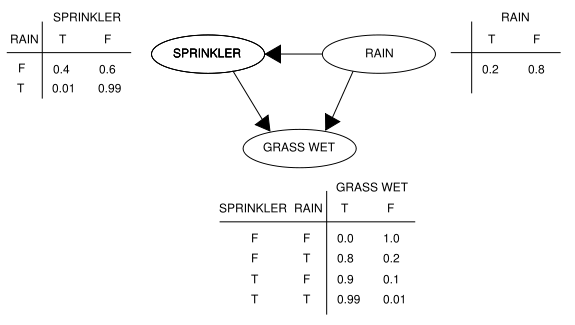
Een bayesiaans netwerk is een structuur, waarin wordt aangegeven welke kans bepaalde gebeurtenissen hebben afhankelijk van andere gebeurtenissen. Dit betekent dat op basis van a-priori kennis (X1 is waar, X2 is niet waar) een uitspraak kan worden gedaan over de kans op gebeurtenis Xi. In formule vorm:

{kind=link}
{kind=link}
Zo geeft de figuur hiernaast de kans weer op nat gras, wat afhangt van de regen en de sprinkler. Wanneer iets bekend is over een onderdeel van het systeem (het regent of het gras is nat) dan heeft dat invloed op de kansen van de ander gebeurtenissen: als het regent is de kans klein dat de sprinkler aan staat.
Het meest kritische onderdeel van het bayesiaanse netwerk is het juist invoeren van de relaties en de bijbehorende kansen. Dit is in feite de a-priori kennis van het systeem. De invoer kan op twee manieren gebeuren, namelijk op basis van een model of op basis van historische gegevens. Een stochastisch model kan worden omgeschreven tot een bayesiaans netwerk door de verschillende relaties als kansen weer te geven. Dit betekent wel dat er bepaalde beperkingen zijn aan het type model dat kan worden gebruikt, vooral doordat alles in gebeurtenissen wordt gedefinieerd. Een bayesiaans netwerk kan niet uitrekenen hoe hoog de intensiteit of hoe lang de reistijd is, maar alleen wat de kans is dat de reistijd of intensiteit boven een bepaalde waarde komt.
De andere mogelijkheid is het gebruik van historische data. Er zijn algoritmes ontwikkeld die op basis van grote hoeveelheden data alle verschillende relaties en de bijbehorende kansen uit kunnen rekenen. Dit zijn zeer zware berekeningen en zij kunnen dan ook maar voor beperkte netwerken worden uitgevoerd. Er is nog een ander groot nadeel van het gebruik van historische data. Gebeurtenissen die in de beschikbare data niet voorkomen hebben ook een kans van nul. Het is dus belangrijk om een zeer complete historische database te hebben.
Als het netwerk eenmaal af is kan het worden gebruikt om datafusie toe te passen. Deze fusie werkt als volgt: De gemeten data wordt als uitgangspunt genomen, dan wordt vervolgens berekend hoe groot de kans op een bepaalde uitkomst is gegeven de gemeten data. De uitkomst waar de grootste waarschijnlijkheid aan wordt toegekend wordt dan voor waar aangenomen. Op die manier worden alleen meetgegevens gebruikt die volgens het model tot een waarschijnlijke uitkomst leiden.
Toepassen van datafusie[]
Het leveren van reisinformatie is een meertraps proces van gegevensinzameling, fusie, value added information en distributie. Daarom moet de datafusiecomponent efficiënt worden ontwikkeld, samen met en in de context van deze andere componenten. Dit ontwikkelingsproces wordt gewoonlijk verwezenlijkt door het gebruik van een gestructureerd systeem ontwikkelingsproces, waarbij deskundigen betrokken zijn en zorgvuldig gerangschikte processtappen worden gevolgd.

{kind=link}
Er bestaat geen standaard benadering voor de ontwikkeling van een datafusiesysteem buiten algemene functionele modellen. Vandaar dat de selectie van de algoritmen voor dataverwerking en datafusie die in het systeem worden gebruikt een iteratief proces is, waarbij het algoritme wordt aangepast totdat gewenste resultaten worden geleverd. Er zijn echter enkele belangrijke ontwikkelingsstappen die de kans op een succesvolle implementatie vergroten. Deze zijn weergegeven in de figuur hiernaast. Hoewel de stappen als een enigszins opeenvolgend proces zijn te zien, is iteratie absoluut vereist. Eventueel kunnen dataminingtechnieken inzicht geven in de gegevenspatronen en de selectie van verdere algoritmen.
Om de reeks van fusiealgoritmen te ontwikkelen is herhaalde toepassing van de stappen in de figuur vereist, voor elk van de belangrijkste functies van de DVM-datafusie. Deze reeks van algoritmen maakt gebruik van de bestaande gegevensbronnen om te komen tot reisinformatie voor de gebruiker of voor een distributeur.
Verder moet bij de uitvoering worden gedacht aan de inpassing in de rest van de DVM-structuren. De datafusie is immers slechts een onderdeel van de verkeersmonitoring. Wanneer het niet goed in de bestaande systemen past is de kans op succesvolle implementatie erg klein. Uiteindelijk moet het systeem zowel apart als ingebed in de andere systemen worden getest en geevolueerd. Pas hierna kan het in gebruik worden genomen, waarbij ook gedacht moet worden aan het monitoren en onderhouden van het systeem.
Voorbeelden van datafusie[]
Er zijn nog maar weinig voorbeelden van uitgebreide datafusie voor verkeersmonitoring systemen. In 'Datafusie', NM magazine 2006-3, p22 wordt echter wel een hypothetisch voorbeeld uitgewerkt, wat zeer illustratief werkt. In het artikel wordt beschreven hoe bijvoorbeeld reistijden zeer robuust en betrouwbaar kunnen worden berekend, door middel van datafusie uit combinaties van inductielussen en Floating Car Data. Een voorbeeld case van een combinatie van Floating Car Data met inductielussen op de A13 is te vinden in het artikel Voorbeeld combinatie FCD met inductielussen. Een grove indicatie van de kosten geeft aan dat hier met lagere kosten een beter monitoringsysteem kan worden opgezet.
Bronnen en Links[]
Uitgebreid rapport over datafusie voor ATIS
'Datafusie', NM magazine 2006-3, p22
Data fusie in de engelse Wikipedia
Data fusie onderzoek in het TRANSUMO ATMO project
Het traffic data fusion project in het ICIS programma, thema ESA (enhanced situation awareness)
Openstaande vragen[]
- een praktisch voorbeeld van datafusie door middel van bayesiaanse netwerken?
- concrete voorbeelden van datafusie?